The Impact of Bias and Fairness on Machine Learning and Large Language Models
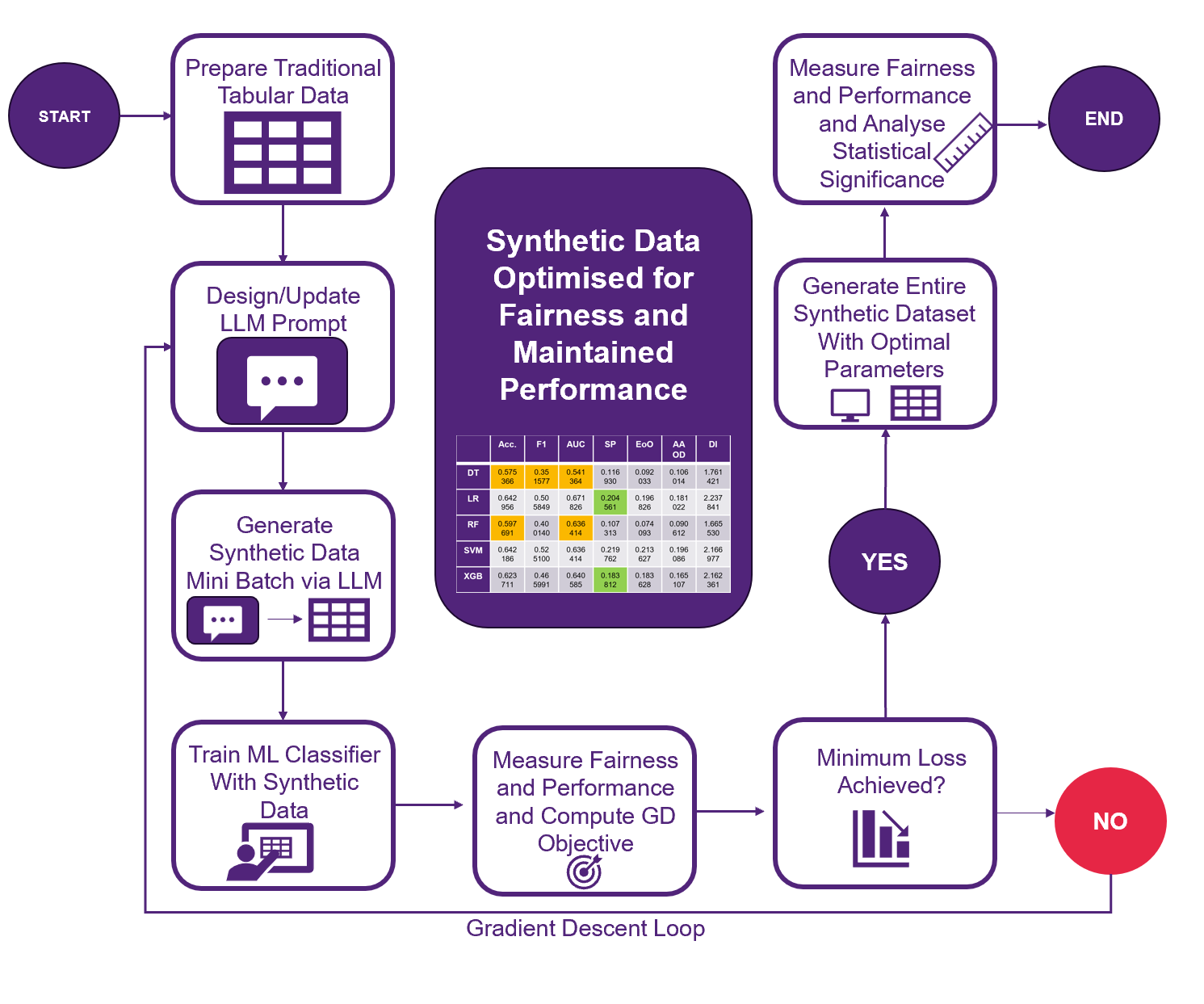
Advancements in the artificial intelligence space have introduced the ability to generate synthetic tabular data for applications where data is scarce or sensitive. Resulting from this however are models which propagate biases from their datasets into downstream tasks, resulting in unfair conclusions. This project investigates how to improve the fairness of Machine Learning classification tasks by generating synthetic tabular data via LLM optimisation technique, particularly Mini-Batch Gradient Descent. This project answers two research questions: does optimisation prompting technique improve fairness in ML classification, and how do these findings compare to ML classification using traditional tabular data. This report documents the proposed methodology, backed by findings in related work and inspired by gaps in the field. Investigation uses biased datasets, COMPAS and Adult, to prompt synthetic data generation via an LLM. Data is then used for iterative optimisation of fairness and performance after being trained by ML classifiers. The project delivers significant results in regards to answering the two developed research questions, and experimental observations, insights and limitations are documented, with future work suggested to further this project.